Publications
2025
-
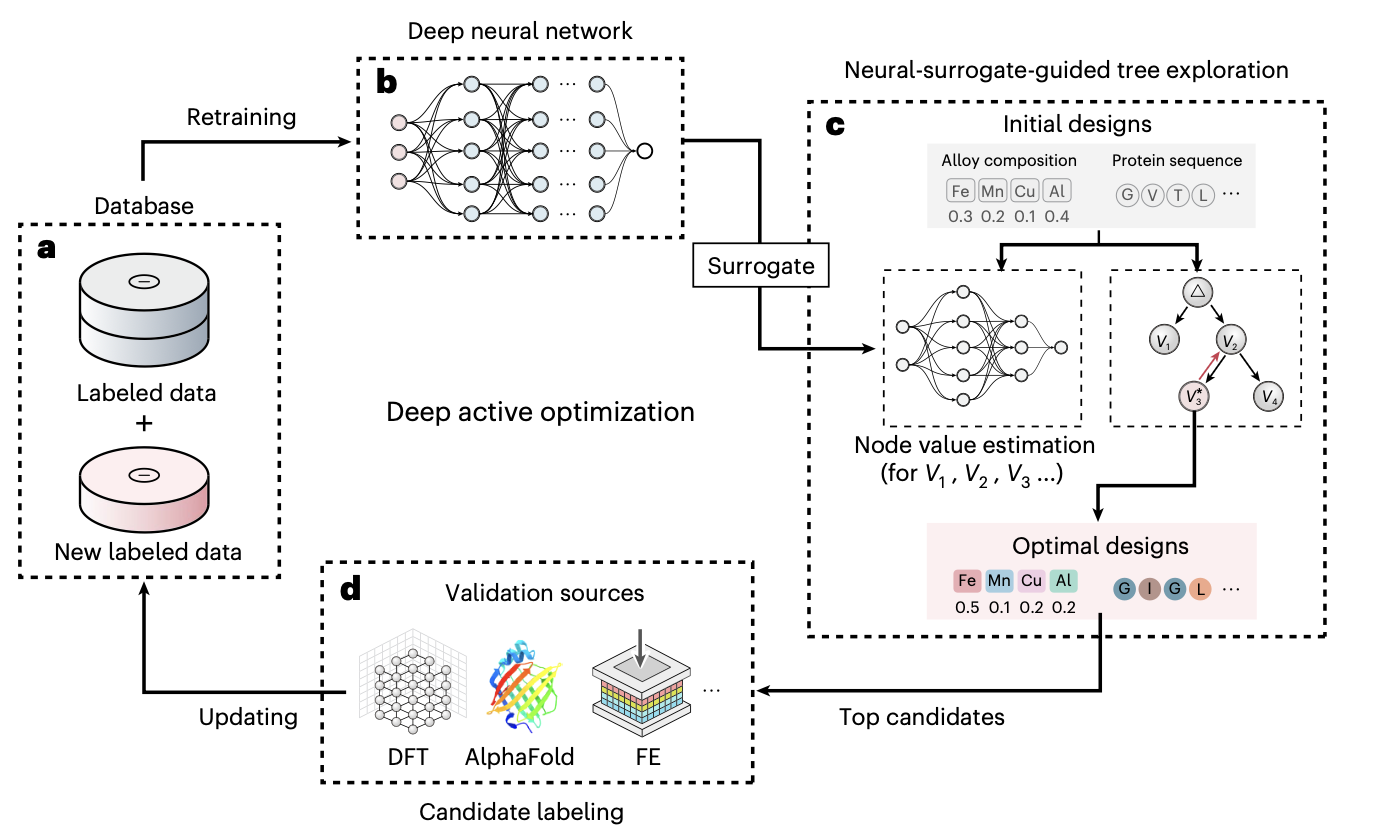 Deep active optimization for complex systemsYe Wei, Bo Peng, Ruiwen Xie, Yangtao Chen, Yu Qin, Peng Wen, Stefan Bauer, Po-Yen Tung, and Dierk Raabe2025
Deep active optimization for complex systemsYe Wei, Bo Peng, Ruiwen Xie, Yangtao Chen, Yu Qin, Peng Wen, Stefan Bauer, Po-Yen Tung, and Dierk Raabe2025Inferring optimal solutions from limited data is considered the ultimate goal in scientific discovery. Artificial intelligence offers a promising avenue to greatly accelerate this process. Existing methods often depend on large datasets, strong assumptions about objective functions, and classic machine learning techniques, restricting their effectiveness to low-dimensional or data-rich problems. Here we introduce an optimization pipeline that can effectively tackle complex, high-dimensional problems with limited data. This approach utilizes a deep neural surrogate to iteratively find optimal solutions and introduces additional mechanisms to avoid local optima, thereby minimizing the required samples. Our method finds superior solutions in problems with up to 2,000 dimensions, whereas existing approaches are confined to 100 dimensions and need considerably more data. It excels across varied real-world systems, outperforming current algorithms and enabling efficient knowledge discovery. Although focused on scientific problems, its benefits extend to numerous quantitative fields, paving the way for advanced self-driving laboratories.
2023
-
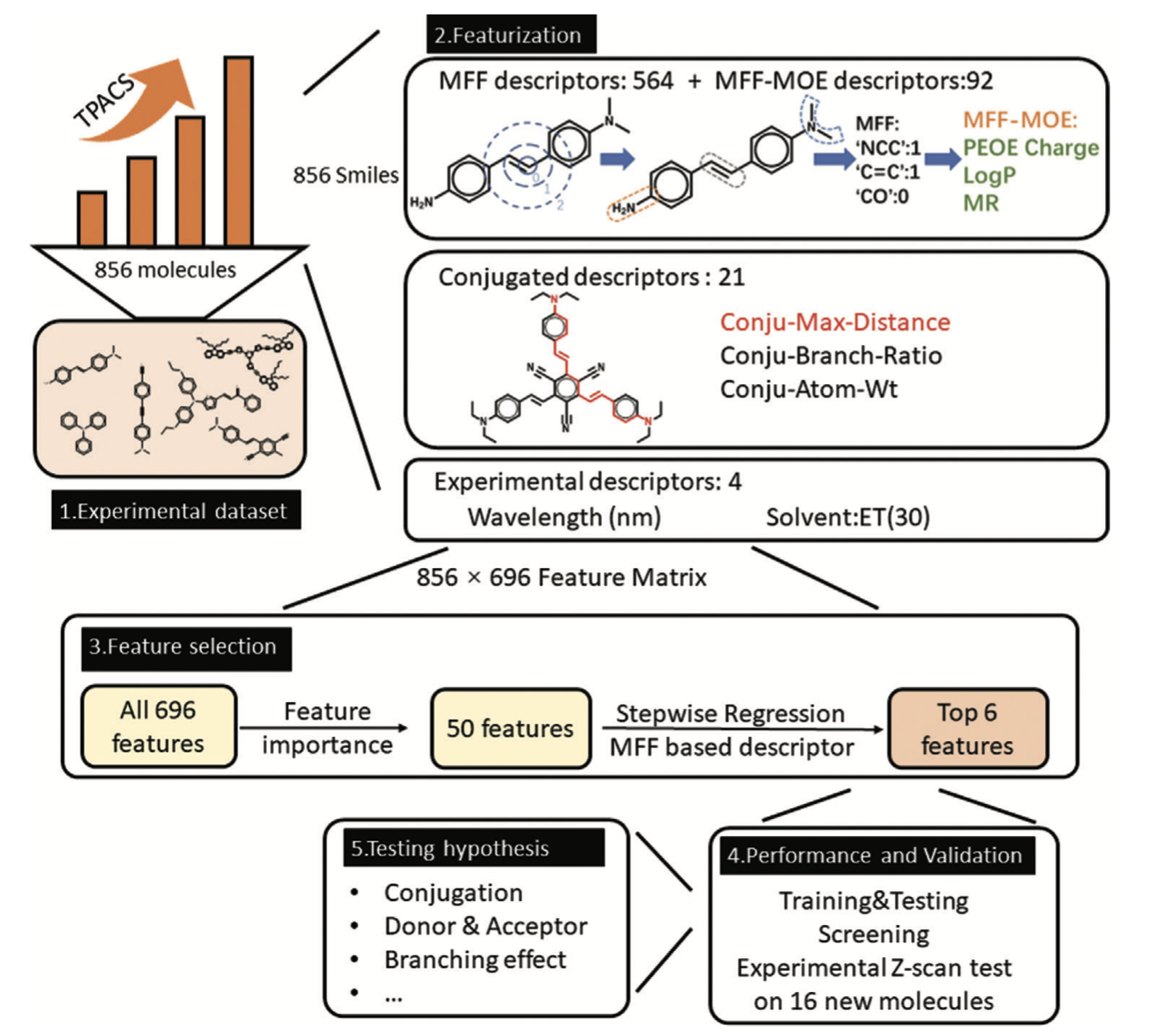 Interpretable Machine Learning of Two-Photon AbsorptionY. Su, Y. Dai, Y. Zeng, C. Wei, Y. Chen, F. Ge, P. Zheng, D. Zhou, P. O. Dral, and C. Wang2023
Interpretable Machine Learning of Two-Photon AbsorptionY. Su, Y. Dai, Y. Zeng, C. Wei, Y. Chen, F. Ge, P. Zheng, D. Zhou, P. O. Dral, and C. Wang2023Molecules with strong two-photon absorption (TPA) are important in many advanced applications such as upconverted laser and photodynamic therapy, but their design is hampered by the high cost of experimental screening and accurate quantum chemical (QC) calculations. Here a systematic study is performed by collecting an experimental TPA database with approximately 900 molecules, analyzing with interpretable machine learning (ML) the key molecular features explaining TPA magnitudes, and building a fast ML model for predictions. The ML model has prediction errors of similar magnitude compared to experimental and affordable QC methods errors and has the potential for high-throughput screening as additionally validated with the new experimental measurements. ML feature analysis is generally consistent with common beliefs which is quantified and rectified. The most important feature is conjugation length followed by features reflecting the effects of donor and acceptor substitution and coplanarity.
-
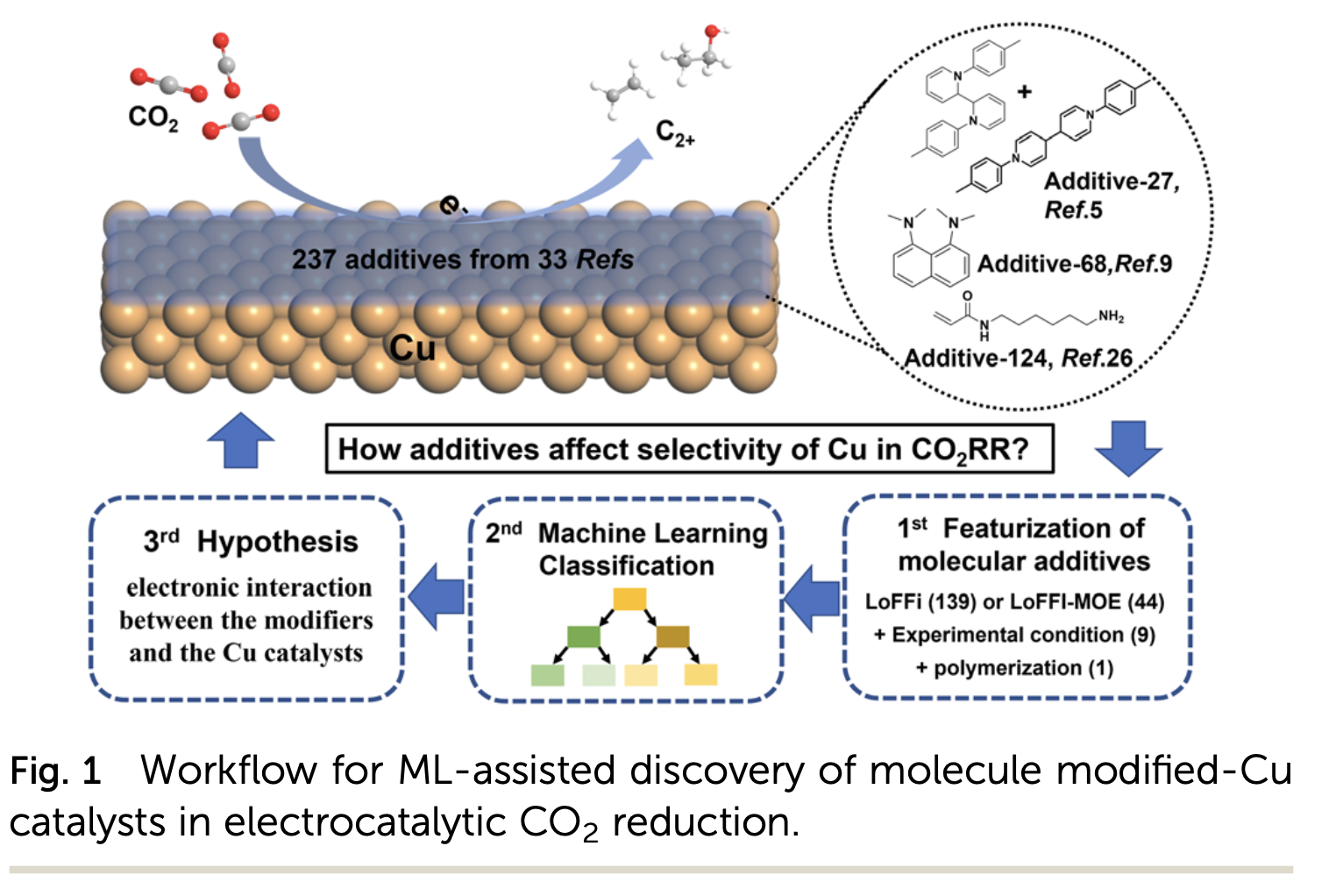 Uncovering the influence of the modifier redox potential on CO2 reduction through combined data-driven machine learning and hypothesis-driven experimentationXinru He, Yuming Su, Jieyu Zhu, Nan Fang, YangTao Chen, Huichong Liu, Da Zhou, and Cheng Wang2023
Uncovering the influence of the modifier redox potential on CO2 reduction through combined data-driven machine learning and hypothesis-driven experimentationXinru He, Yuming Su, Jieyu Zhu, Nan Fang, YangTao Chen, Huichong Liu, Da Zhou, and Cheng Wang2023In recent years, Cu-based catalysts have attracted attention for their ability to reduce CO2 into various C2+ products. Surface organic modification of Cu has been shown to tune the selectivity effectively. However, such a modification effect is complex, especially considering the diverse catalyst preparation procedures and testing conditions. In this work, we analyzed the literature data on the catalytic performance of organics-modified Cu and bare Cu for comparison. We calculated the change in the faradaic efficiency of C2+ products after organic modification. We analyzed these changes using machine learning, which showed an unexpected correlation between the electronic structure of the modifiers and the faradaic efficiency. To test this data-inspired hypothesis, we experimentally constructed a series of alkyne-conjugated polymers as the Cu surface modifiers, confirming such a correlation between the monomer reduction potential and the C2+ selectivity of the modified Cu catalysts. Our work demonstrates the significance of combining data-driven and hypothesis-driven approaches to uncover new insights into the design of effective CO2 electroreduction catalysts.